All Categories
Featured
Table of Contents
What is necessary in the above curve is that Degeneration provides a greater value for Details Gain and thus create even more splitting compared to Gini. When a Decision Tree isn't complex enough, a Random Forest is generally used (which is nothing even more than several Decision Trees being grown on a subset of the data and a last bulk voting is done).
The number of clusters are established using an elbow contour. Understand that the K-Means formula enhances locally and not globally.
For even more details on K-Means and other forms of without supervision knowing formulas, take a look at my other blog site: Clustering Based Without Supervision Knowing Semantic network is just one of those neologism formulas that every person is looking in the direction of nowadays. While it is not possible for me to cover the complex details on this blog site, it is necessary to understand the basic systems in addition to the idea of back propagation and vanishing slope.
If the study need you to build an interpretive model, either pick a various model or be prepared to explain how you will certainly find how the weights are adding to the outcome (e.g. the visualization of surprise layers during photo recognition). Finally, a single design might not precisely determine the target.
For such circumstances, a set of numerous designs are used. An example is provided listed below: Right here, the designs remain in layers or heaps. The output of each layer is the input for the next layer. One of one of the most common way of examining design performance is by calculating the percentage of documents whose documents were anticipated precisely.
Here, we are aiming to see if our model is as well intricate or not facility sufficient. If the model is simple adequate (e.g. we made a decision to use a direct regression when the pattern is not direct), we wind up with high bias and low variation. When our model is as well intricate (e.g.
Creating Mock Scenarios For Data Science Interview Success
High variation since the result will certainly differ as we randomize the training information (i.e. the version is not extremely steady). Currently, in order to identify the version's complexity, we use a learning contour as revealed below: On the understanding curve, we vary the train-test split on the x-axis and calculate the accuracy of the model on the training and validation datasets.
Faang Interview Preparation Course
The more the contour from this line, the greater the AUC and better the version. The highest a version can obtain is an AUC of 1, where the curve forms a right angled triangle. The ROC contour can also aid debug a version. For instance, if the lower left edge of the contour is better to the arbitrary line, it implies that the design is misclassifying at Y=0.
Additionally, if there are spikes on the curve (as opposed to being smooth), it indicates the model is not secure. When taking care of fraudulence designs, ROC is your friend. For more details check out Receiver Operating Attribute Curves Demystified (in Python).
Information scientific research is not simply one area but a collection of fields used together to construct something special. Data scientific research is concurrently maths, statistics, problem-solving, pattern finding, interactions, and business. Since of how broad and adjoined the field of data scientific research is, taking any action in this field may appear so complex and complex, from trying to discover your means via to job-hunting, looking for the correct duty, and lastly acing the meetings, but, despite the complexity of the area, if you have clear steps you can comply with, getting involved in and getting a task in data scientific research will certainly not be so confusing.
Information science is everything about mathematics and stats. From likelihood concept to straight algebra, maths magic allows us to understand information, find fads and patterns, and build algorithms to predict future information scientific research (Tools to Boost Your Data Science Interview Prep). Math and statistics are essential for data scientific research; they are always inquired about in data scientific research interviews
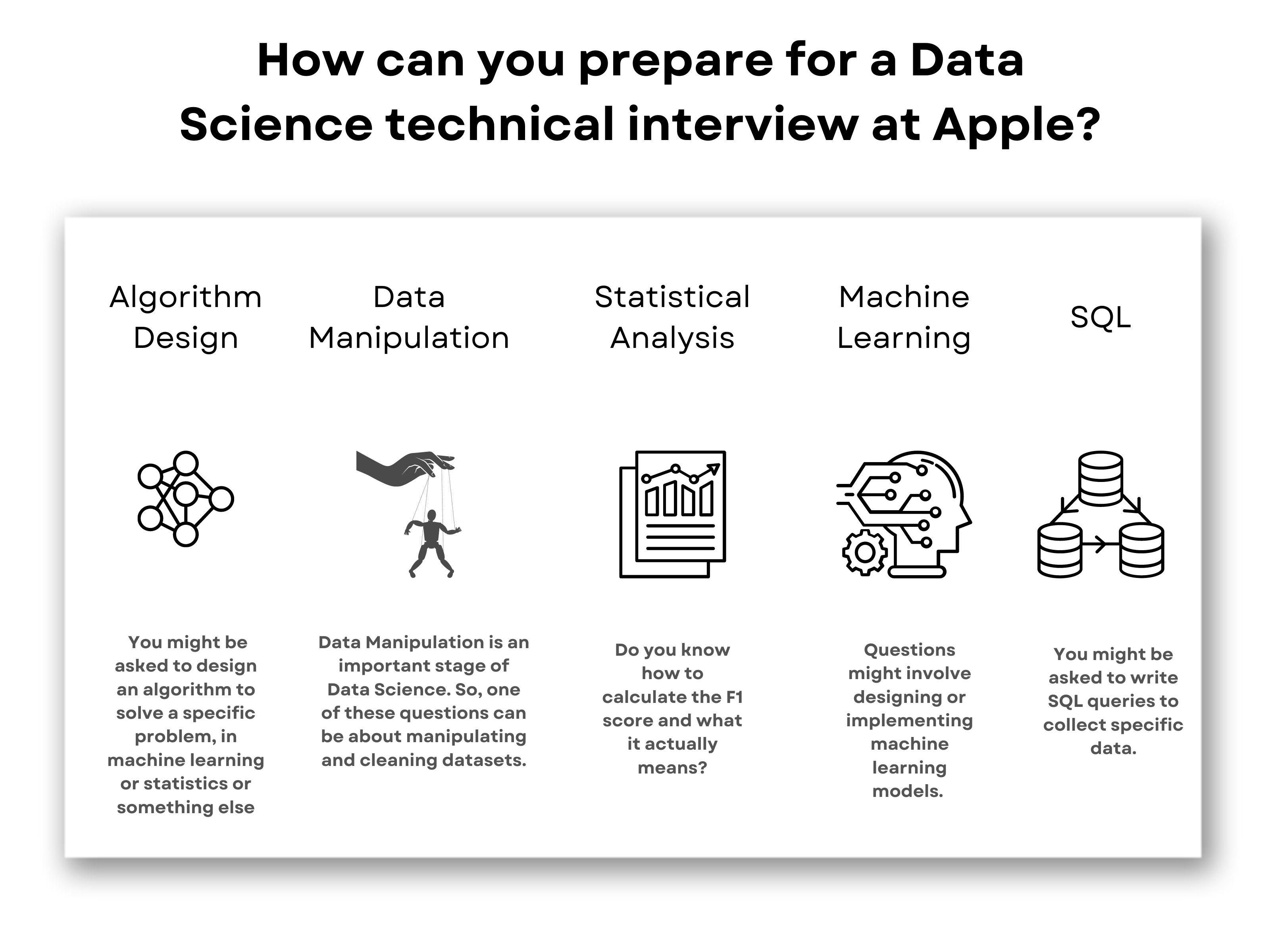
All abilities are utilized day-to-day in every data scientific research project, from information collection to cleaning to exploration and analysis. As quickly as the job interviewer examinations your capacity to code and think of the various algorithmic troubles, they will provide you data science problems to test your data handling skills. You usually can pick Python, R, and SQL to tidy, discover and analyze a provided dataset.
Amazon Interview Preparation Course
Artificial intelligence is the core of lots of information science applications. Although you might be composing artificial intelligence formulas just often on the task, you require to be very comfy with the fundamental equipment finding out algorithms. In enhancement, you need to be able to suggest a machine-learning algorithm based on a specific dataset or a details problem.
Validation is one of the major steps of any kind of data scientific research project. Making certain that your design behaves correctly is essential for your firms and clients since any error might cause the loss of money and resources.
, and standards for A/B tests. In enhancement to the concerns concerning the particular building blocks of the field, you will always be asked general data scientific research inquiries to evaluate your capacity to place those building blocks with each other and establish a total job.
The information science job-hunting process is one of the most tough job-hunting processes out there. Looking for work functions in information science can be hard; one of the major factors is the vagueness of the function titles and summaries.
This uncertainty just makes preparing for the meeting a lot more of a headache. Besides, exactly how can you prepare for an obscure function? By practising the standard building blocks of the field and then some basic concerns concerning the various algorithms, you have a robust and powerful mix ensured to land you the task.
Preparing for data science interview questions is, in some respects, no various than preparing for a meeting in any other sector. You'll look into the company, prepare solution to usual meeting concerns, and assess your portfolio to use throughout the interview. Preparing for a data scientific research interview entails even more than preparing for inquiries like "Why do you assume you are certified for this placement!.?.!?"Data researcher meetings consist of a lot of technological topics.
Real-time Data Processing Questions For Interviews
This can include a phone meeting, Zoom interview, in-person interview, and panel interview. As you might anticipate, a number of the interview inquiries will certainly concentrate on your hard skills. Nevertheless, you can likewise anticipate questions concerning your soft abilities, as well as behavioral interview questions that assess both your hard and soft skills.
A certain technique isn't necessarily the ideal simply because you've utilized it in the past." Technical abilities aren't the only sort of data scientific research meeting concerns you'll run into. Like any kind of meeting, you'll likely be asked behavior concerns. These inquiries assist the hiring manager comprehend exactly how you'll utilize your skills on duty.
Below are 10 behavior concerns you could encounter in an information researcher interview: Tell me regarding a time you used data to cause alter at a work. Have you ever before needed to discuss the technological details of a job to a nontechnical individual? How did you do it? What are your pastimes and passions beyond data science? Inform me regarding a time when you worked with a long-term information project.
Recognize the different types of interviews and the general process. Study data, possibility, theory screening, and A/B screening. Master both fundamental and advanced SQL inquiries with functional issues and simulated meeting questions. Use vital collections like Pandas, NumPy, Matplotlib, and Seaborn for data adjustment, analysis, and fundamental artificial intelligence.
Hi, I am currently preparing for a data scientific research interview, and I've found an instead difficult inquiry that I can utilize some aid with - Leveraging AlgoExpert for Data Science Interviews. The concern involves coding for a data scientific research trouble, and I think it requires some sophisticated abilities and techniques.: Given a dataset including info concerning customer demographics and acquisition history, the task is to anticipate whether a consumer will purchase in the following month
Real-time Scenarios In Data Science Interviews
You can't perform that activity currently.
The need for data scientists will certainly grow in the coming years, with a forecasted 11.5 million work openings by 2026 in the United States alone. The area of data science has actually rapidly gained appeal over the past years, and as a result, competition for information scientific research tasks has actually ended up being fierce. Wondering 'Exactly how to get ready for information scientific research meeting'? Continue reading to discover the solution! Resource: Online Manipal Take a look at the work listing extensively. Go to the company's official site. Examine the rivals in the industry. Understand the company's values and culture. Investigate the company's most recent accomplishments. Find out about your potential job interviewer. Before you dive into, you need to recognize there are certain sorts of meetings to plan for: Interview TypeDescriptionCoding InterviewsThis meeting examines understanding of different topics, including device understanding techniques, sensible data extraction and control difficulties, and computer science principles.
{kind=link}
Table of Contents
Latest Posts
How To Overcome Coding Interview Anxiety & Perform Under Pressure
The Best Mock Interview Platforms For Faang Tech Prep
How To Explain Machine Learning Algorithms In A Software Engineer Interview
More
Latest Posts
How To Overcome Coding Interview Anxiety & Perform Under Pressure
The Best Mock Interview Platforms For Faang Tech Prep
How To Explain Machine Learning Algorithms In A Software Engineer Interview